Optimizing Rc memory usage in Rust
Recently I tried to optimize some memory intensive Rust code. It turned out to be harder than I expected, but I learned some interesting things about Rust memory usage along the way, so I am writing my story in case anyone else finds it useful.
The core algorithm of my code involves manipulating long strings formed by repeated concatenation with each other. In order to be efficient, the strings need to be represented implicitly as a tree (actually a DAG) of concatenated strings. Therefore, I defined a data structure to represent them in the natural way:
enum LongStr {
Leaf(Vec<u8>),
Concat(RcStr, RcStr),
}
type RcStr = Arc<LongStr>;
I used Arc because my code is parallel, but everything that follows applies equally to Rc. Anyway, my code creates billions of these RcStrs, enough to exhaust even 32GB of RAM, so it is important to make this type as small as possible.
RcStr itself is already optimal, as it is just a pointer, and LongStr::Concat is just two pointers to subnodes. However, there is one hidden source of bloat: the weak reference counts. When you create an Arc<T> or Rc<T>, it doesn’t just allocate space for the T, it also needs space for the reference counts.
struct ArcInner<T: ?Sized> {
strong: atomic::AtomicUsize,
weak: atomic::AtomicUsize,
data: T,
}
However, there are actually two reference counts. The second one is needed to support weak pointers, which I wasn’t using. Therefore, there’s 8 bytes of wasted memory per allocated node, which is an obvious target for optimization.
I copied the standard libraries’ implementation of Arc, fixed up the imports and crate attributes until it compiled, removed the weak reference count and all the weak pointer related functionality, and eagerly reran the code to compare memory usage… and there was no change. That’s when things got really interesting/frustrating.
My first idea was that either it wasn’t using my modified Arc, or the compiler was somehow genius enough to optimize away the weak reference count. Therefore, I added an unused dummy field of [u8; 100] to my copy of ArcInner and sure enough, the memory usage shot up.
Then I experimented with changing the size of dummy field to see how it affected memory usage. I set it to 0 bytes, 16 bytes, 32 bytes, and 64 bytes, and got the linear increase in memory usage that you’d expect.
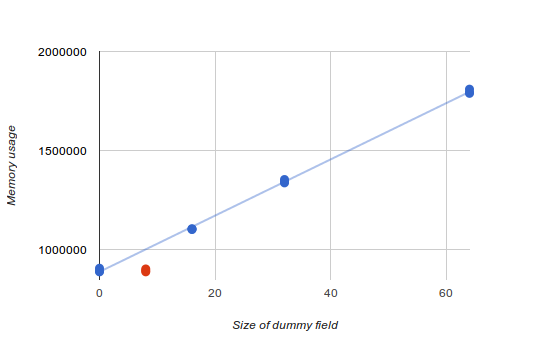
However, when the dummy field was 8 bytes, simulating the removed weak reference count, the memory usage was the exact same as with 0 bytes! (This is highlighted in red on the above graph). It’s almost like the gods of optimization were taunting me, specifically pessimizing the one case I actually cared about, 0 bytes vs 8 bytes.
My next idea was that perhaps there was some padding or alignment issue that was causing size_of
cargo rustc --release -- -Z print-type-sizes
This produces output like the following.
print-type-size type: `weakless::arc::ArcInner<LongStr>`: 40 bytes, alignment: 8 bytes
print-type-size field `.strong`: 8 bytes
print-type-size field `.dummy`: 0 bytes
print-type-size field `.data`: 32 bytesprint-type-size type: `weakless::arc::ArcInner<LongStr>`: 48 bytes, alignment: 8 bytes
print-type-size field `.strong`: 8 bytes
print-type-size field `.dummy`: 8 bytes
print-type-size field `.data`: 32 bytes
LongStr was 32 bytes, bigger than I expected, but I figured I’d worry about that later. The important part is that this showed that there were no weird alignment or padding issues — ArcInner actually goes from 40 to 48 bytes when the size of dummy is increased from 0 to 8, just as expected.
Eventually, I realized that there is one other possible source of padding, which operates at a lower level than even the compiler — the allocator. In order to reduce fragmentation, the default allocator, jemalloc, groups the sizes of small objects into bins. When you allocate x bytes, it doesn’t actually give you x bytes exactly. Instead it rounds up to the nearest bin size.
I looked up the bin sizes of jemalloc, and sure enough, there’s a bin size of 48, but no bin of size 40. Therefore, allocating 40 bytes and 48 bytes both result in 48 bytes of actual memory usage.
In fact, the list of bin sizes from 16–128 is [16, 32, 48, 64, 80, 96, 112, 128]. This means that when I changed dummy from 0, to 16, to 32, to 64 bytes, the size of ArcInner struct went from 40, to 56, to 72, to 104 bytes, which resulted in using bin sizes of 48, 64, 80, and 112. In each case, the bin overhead was the same (8 bytes), so I got the nice linear pattern pretty much by luck.
At this point, I had solved the mystery, but I still hadn’t succeeded in reducing memory usage. Luckily, there was a separate issue I noticed earlier. LongStr was 32 bytes, which seems bigger then necessary, since the Concat nodes only hold two pointers (8 bytes each). Even with an 8 byte enum discriminant, that only accounts for 24 bytes.
The trick is that enums are sized to hold the largest variant, and in this case, the Leaf variant was unnecessarily big. It holds a Vec, which contains a pointer, a length field, and a capacity field, for a total of 24 bytes, bringing the enum to 32 bytes. However, the capacity field is completely useless in this case. You can get rid of it by switching from Vec
enum LongStr {
Leaf(Box<[u8]>),
Concat(RcStr, RcStr),
}
type RcStr = Arc<LongStr>;
This brings LongStr down to 24 bytes, which combined with the removal of the weak reference count, means that ArcInner<LongStr> is now only 32 bytes, the size of the next smallest jemalloc bin. Therefore, every allocated node is now using 33% less memory, leading to huge memory and speed gains in the overall code.
Anyway, this optimization turned out to be a lot more involved than I expected, but I learned a lot of interesting details about Rust in the process of debugging it, and I hope this information is helpful to others.
Update: System Allocator
Someone suggested that I try using the system allocator instead of jemalloc. It turns out that this was easier to do than I expected. All you have to do is put this at the top of your crate root.
#![feature(alloc_system)]
extern crate alloc_system;
Unfortunately, the system allocator used significantly more memory than jemalloc, to the point where it was so obviously unusable that I didn’t bother trying to get concrete numbers. Note that this is with all the optimizations mentioned above, since I couldn’t be bothered to undo them, but if system malloc can’t handle the optimized code, it certainly couldn’t handle the original version.
Update 2: Insanity Mode
The reason for going to all this trouble with the Arcs is to reclaim memory when it is no longer referenced, but what if you just deliberately leaked everything and used &'static LongStr instead of Arc<LongStr>?
fn leak_allocate<T>(val: T) -> &'static T {
let b: Box<_> = Box::new(val);
unsafe{&*Box::into_raw(b)}
}
Leaking memory has the benefit that you no longer need all those reference counts, reducing the size of each node to 24 bytes. This on its own wouldn’t provide a benefit due to the bin size issue. However, the only reason each ArcInner was individually allocated was so that they could be individually freed. Leaking memory means you can just allocate all your nodes contiguously in a giant list of arrays.
fn arena_allocate(val: LongStr) -> &'static LongStr {
thread_local! {
static ARENA: &'static TypedArena<LongStr> = leak_allocate(TypedArena::new());
}
ARENA.with(|ar| {
ar.alloc(val)
})
}
The obvious downside to leaking all the memory is that you use up memory, resulting in extra paging. In my case, I have 32gb of RAM and a 32gb swap partition (on SSD). In theory, if a page of consecutive LongStr are no longer referenced, Linux should notice that it isn’t being accessed and eventually page it out of memory.
Anyway, it’s an interesting idea, but it turned out to be slower than using reference counting in practice, presumably due to all the extra paging. It also relies on having sufficient swap space.
Update 3: Bit packing
Another commenter pointed out that it is possible to go all the way down to 16 bytes with some unsafe code. The trick is that on x64, (userland) pointers are limited to a 47 bit address space. This means that two pointers plus an enum discriminant can be packed into 12 bytes, leaving 4 bytes for an atomic reference count.
I actually tried implementing this, but it crashed and I didn’t feel like trying to debug why. Such are the perils of writing clever unsafe code, I suppose.